관계형 데이터베이스의 필요성
왜 관계형데이터가 필요한가?
"데이터가 중복된다"라는 것은 퍼포먼스와 유지보수의 측면에서 개선의 여지가 있다는 강력한 증거.
유지보수가 용이해진다.
'관계'가 없다면?
데이터가 중복되면 여러가지 문제점이 발생할 수 있다.
굉장히 복잡하고 대용량의 데이터가 다수개.. 천만개의 레코드에서 동일하게 등장한다고 생각해보자
1) 데이터들에 대한 수정이 필요할 때, '수정'하는 행위를 n번 반복해야된다.
또한 2) 데이터가 많을 때, 특정 데이터값에 대해서 동일한 값임을 확신하기 어렵다. 결과적으로 기술적, 경제적으로 손해이다.
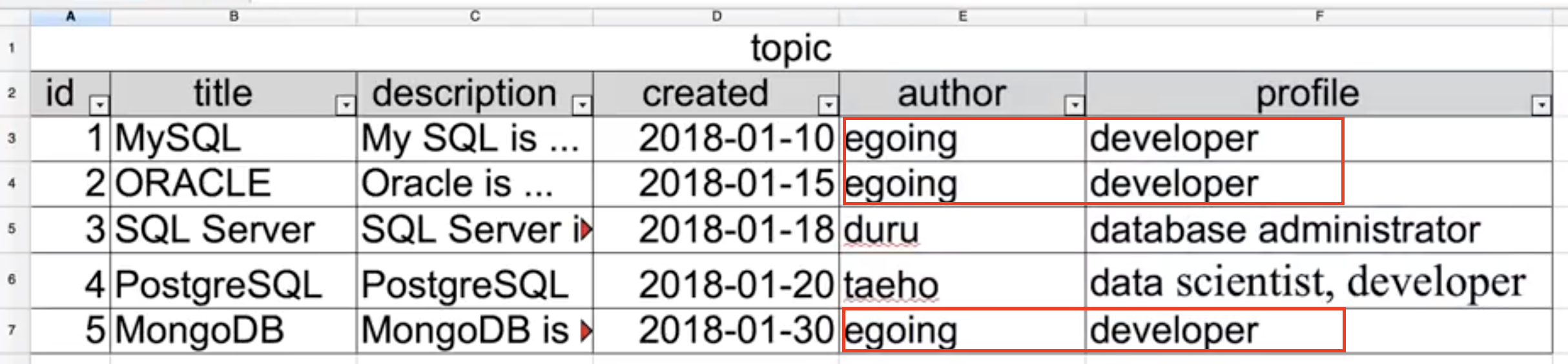
위 'topic' 표에서 'author(저자)'들에 대한 정보를 별도의 'author'라는 이름의 표로 분리한다. author, profile 정보를 담는 테이블이다.
'topic' 표의 구조를 수정한다. author와 profile에 대한 정보를 삭제하고 'author_id' 라는 형식의 정보를 담도록 한다.

topic 테이블에 존재하던 중복된 데이터들은 사라지고, 각각의 데이터들에 대한 author 테이블의 식별자인 id 값으로 대체되었다.
author 테이블의 'egoing' -> '이고잉' 으로 데이터를 수정한다고 할 때, 이 전에는 topic 테이블에서 데이터 갯수 만큼 수정해야 했지만, 이제는 author 테이블에서 한 번만 수정하면, topic 테이블은 author 테이블을 참조하고 있기 때문에 모든 데이터가 갱신돼서 보여진다.
=> "유지보수가 용이해졌다."
저자의 이름과 프로필이 같은 경우, 이전에는 id 1, 2, 5 번의 저자가 동일 인물인지 알 수 없었다.
'관계형표'에서는 author의 id 1번과 4번의 이름과 프로필이 동일하지만 다른 사람임을 알 수 있고, topic 테이블에서 1,2번과 5번이 서로 다른 author_id 값을 가지고 있으므로 서로 다른 저자라는 것을 확신할 수 있다.
※ Trade-off
장점이 생기긴 했지만, 장점만 생긴 것은 아니다.
하나의 데이터베이스는 직관적으로 데이터를 볼 수 있지만, 관계형에선 새로운 데이터베이스를 참조하여 확인해야하는 불편함이 있다.
=> "JOIN" MySQL을 통해서, 중복을 피해 별도의 테이블로 데이터를 저장하면서도 한 눈에 하나의 테이블로 데이터를 볼 수 있게 된다.
'코딩공부 > DATABASE2 - MySQL' 카테고리의 다른 글
| [7] 인터넷과 데이터베이스 (0) | 2019.09.18 |
|---|---|
| [6] 테이블 분리, JOIN (0) | 2019.09.18 |
| [4] MySQL의 CRUD - INSERT, SELECT, UPDATE, DELETE (0) | 2019.09.18 |
| [3] MySQL 테이블의 생성 (0) | 2019.09.18 |
| [2] MySQL의 구조 (0) | 2019.09.18 |



