가장 간단한 데이터를 저장하고 오픈할 수단 'file'
파일의 성능이나 보안이나 편의성의 한계를 가지고 있어서, 파일이 가진 한계를 극복하기 위해서 전문화된 소프트웨어가 "database"
MySQL, Oracle, SQL Server, Postgresql, MongoDB
데이터베이스는 거대하고 복잡하고 위험한 데이터를 다루기 위해서 고안된 도구이다.

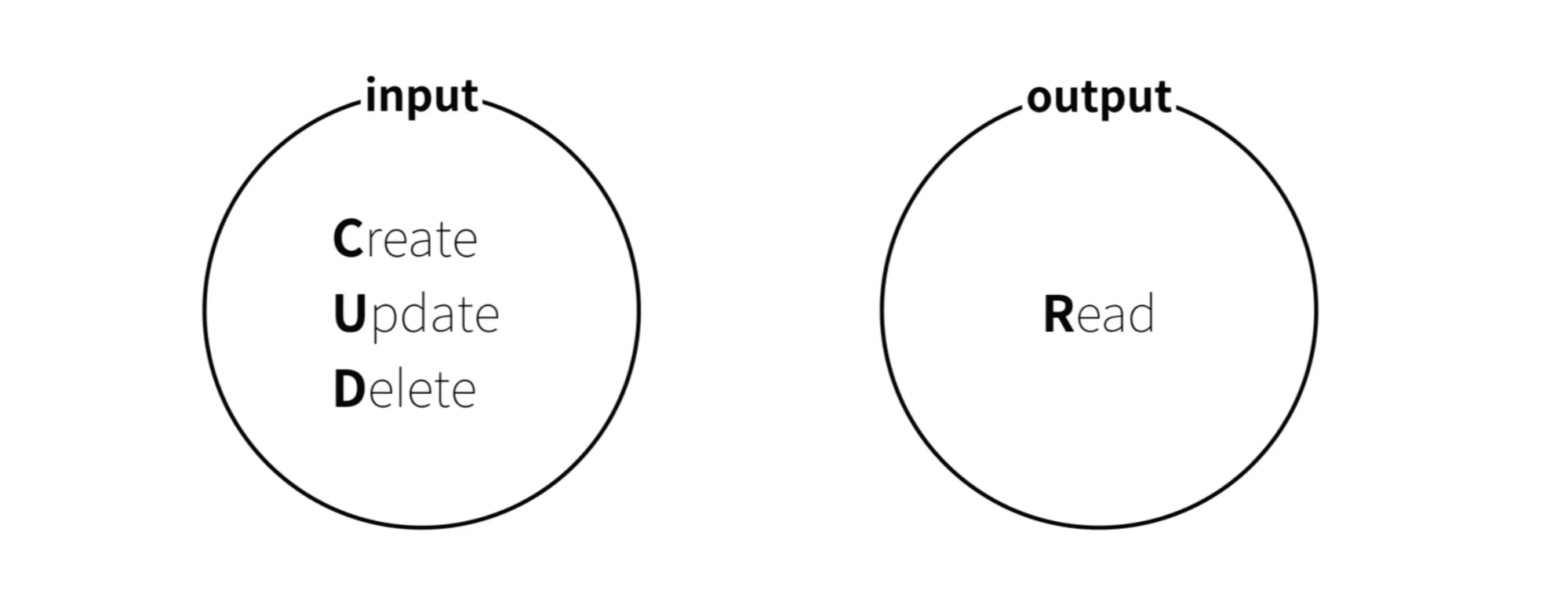
데이터베이스의 본질 - CRUD
데이터베이스는 매우 방대한 기능을 가지고 있는 정보 도구이다.
"아무리 복잡한 기술도 그 중심에 자리 잡고 있는 핵심은 복잡하지 않다." 어떤 데이터베이스를 사용하던 이 바닥에서 데이터베이스의 데이터를 어떻게 입력하고 출력하는가를 따져보는 것이다.
입력(input)에는 Create(생성), Update(수정), Delete(삭제), 출력(output)에는 Read(읽기)가 있다.
데이터 관련해서 CRUD 네 가지 작업이 데이터 관련해서 거의 모든 기능이라고 보면 된다. 나머지는 CRUD를 보좌하는 부가기능이다.
file vs DATABASE
CRUD : 데이터베이스의 핵심적인 작업
file > Spreadsheet > Database 로의 발전

file
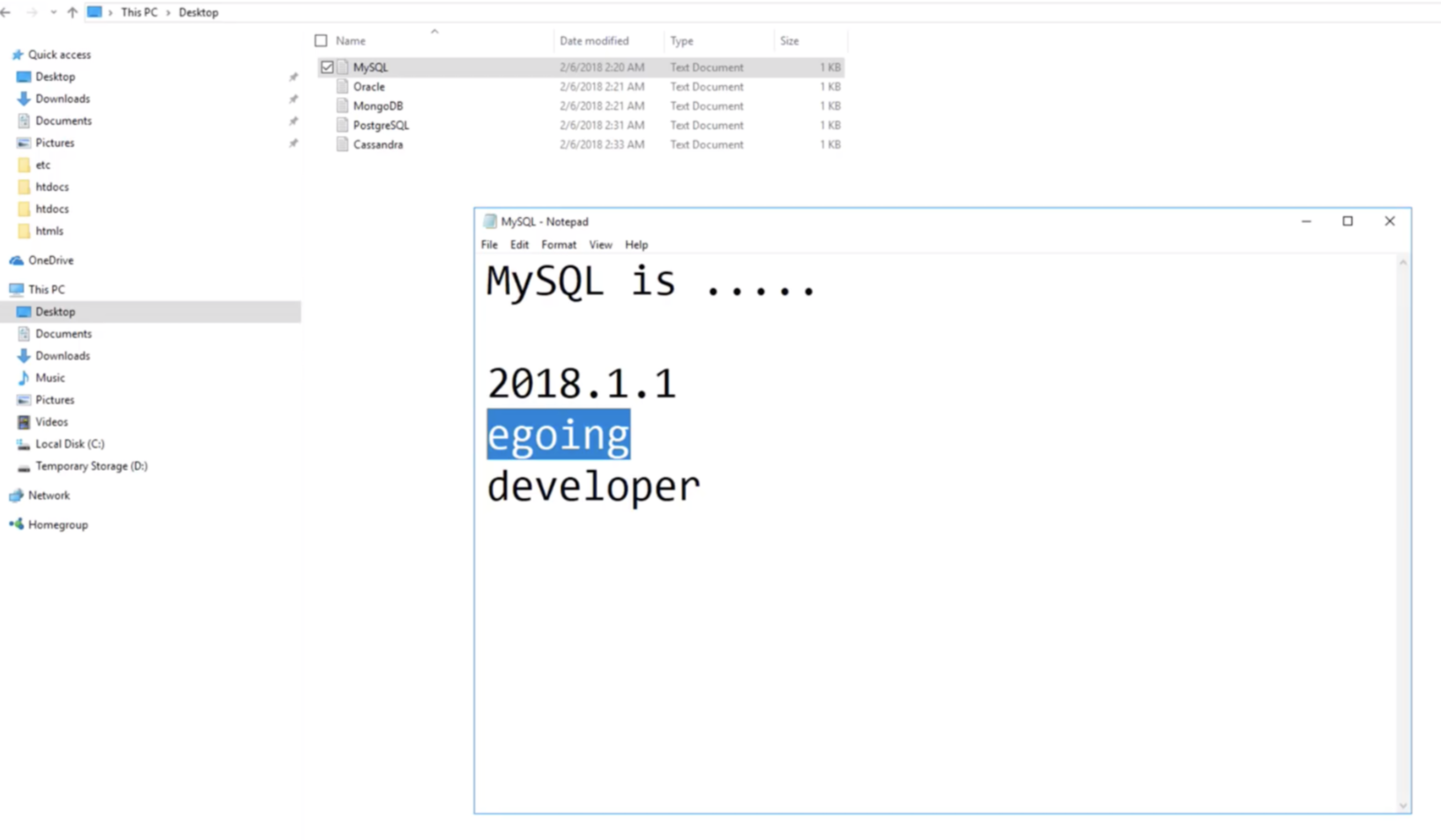
파일로 본문, 생성 날짜, 작성인, 저자 프로필 등의 정보를 저장하였다. 이때, 작성 날짜 기준으로 파일 목록이 정렬돼서 싶다면...?
작성인이 egoing인 파일들만 따로 보고 싶다면...? (검색을 이용할 시 본문에 'egoing' 문자가 섞여 있다면 노이즈가 섞여 나올 수 있다.)
본문만 보이도록 하고 나머지 정보를 숨기고 싶다면...? 파일로는 불가능하다.
스프레드 시트
파일로 불가능한 기능을 사용할 수 있다.
제품군
- 마이크로소프트 - Exel
- 구글 - 구글 문서도구
- 무료 오픈소스 제품 - 오픈오피스
정보들을 정리 정돈하기 위해서 구조를 먼저 작성한다. 정리 정돈했을 때 중요한 효과들을 얻을 수 있다.
데이터의 행의 1억 개라고 생각해보자. 수많은 레코드 중에서 'egoing'이라고 하는 저자가 작성한 글만을 보고 싶다면 '필터(Filter)' 기능을 이용하면 된다. 생성 날짜를 기준으로 파일들의 목록을 보고 싶다면 '정렬(Sort)' 기능을 이용하면 된다.
데이터를 구조적으로 데이터를 저장했을 때 우리가 얻을 수 있는 효과 "데이터를 가공하기 용이하다."
데이터베이스
프로그래밍 적으로 (컴퓨터 언어를 이용해서) 데이터를 추가, 수정, 삭제하고 읽을 수 있다는 점을 전문적인 데이터베이스 소프트웨어들은 가지고 있다. 그럼으로써 얻을 수 있는 장점은 "자동화할 수 있다."
사람이 일일이 작성하지 않고도 어떤 조건에 따라 자동으로 데이터를 CRUD 작업할 수 있다.
스프레드시트 vs 데이터베이스
공통점
MySQL과 같은 '관계형 데이터베이스'의 중요한 특징은 스프레드시트와 마찬가지로 데이터를 '표'의 형태로 표현해준다.
'기능'은 비슷하다. Filter, Sort ...
차이점
데이터베이스는 코딩(컴퓨터 언어)을 통해서 제어할 수 있다.
데이터베이스에 저장된 데이터를 웹, 앱을 통해서 사람들에게 공유할 수 있다. 데이터를 빅데이터, 인공지능을 이용해서 분석할 수 있다.
웹사이트의 정보를 데이터베이스에 담을 때 얻을 수 있는 효과
1. 데이터베이스에 있는 정보를 전 세계 누구나 이 웹사이트에 접속해서 볼 수 있다.
2. 데이터베이스를 직접 제어하지 않아도 사용자가 정보를 입력하면 데이터베이스가 갱신된다.
데이터베이스 선택 시 고려사항
통계를 기반으로 공부할 것을 선택해보면 좋다.
database ranking 2019
https://db-engines.com/en/ranking
DB-Engines Ranking
Popularity ranking of database management systems.
db-engines.com

DBMS : 데이터베이스 이름
Database Model : 데이터베이스 형식
- Relational DBMS 관계형 데이터베이스 관리 시스템 : 데이터베이스 시장의 절대강자는 관계형 데이터베이스이다.
- nosql : MongoDB는 계속해서 성장하고 있는 DB. 관계형 데이터 베스가 아닌 완전히 다른 형식
관계형 데이터베이스를 하나 먼저 공부하고, 관계형 데이터베이스가 아닌 DB를 배워 나기길 추천
두 개의 데이터베이스에 공통적을 존재하는 특성과, 다른 특성을 가진 부분을 비교하면 된다.
공통적을 존재하는 특성은 중요한 본질적인 내용일 가능성이 높고, 다른 특성은 데이터베이스에 대한 고정관념을 환기시켜줄 수 있다.
Oracle : 아주 오랫동안 데이터베이스 시장에서 절대 강자로 군림해 왔던 데이터베이스
자금력이 있는 대기업이나 정부 관공서에서 사용한다. 매우 비싼 비용, 데이터베이스의 기술 지원과 같은 경우 컨설팅 비용이 비싸다.
( 개인적으로 사용하거나, 소기업, 금융과 같은 중요 데이터를 처리하는 게 아니라면 비추천)
MySQL : 무료. 오픈소스.
관계형 데이터베이스를 이용하고 싶으면서, 자금이 많지 않아 개인적인 사용, 소기업, sns와 같이 대규모의 데이터가 생성되지만 데이터의 신뢰성이 아주 중요하지 않은 기업에게 추천
MongoDB : Document store라는 Database Model이다.
2010부터 관계형 데이터베이스가 아닌 데이터베이스가 쏟아져 나왔다. sns가 등장, 사물인터넷 등장, 수많은 다양한 종류의 데이터들이 쏟아져 나올 예정이다. 관계형 데이터베이스에 모든 데이터베이스가 낑겨들어가면, 거기에 잘 맞지 않는 데이터베이스들 입장에서는 관계형 데이터베이스가 일종의 '억압'으로서 작용할 수가 있다.
2010년부터 nosql이라는 흐림이 등장했다. nosql이라는 흐름에서 가장 중요한 특징은 "관계형 데이터베이스가 아닌 다양한 데이터베이스가 폭발적으로 만들어지고 있고 성장하고 있다."
'코딩공부 > DATABASE2 - MySQL' 카테고리의 다른 글
| [5] 관계형 데이터베이스의 필요성 (0) | 2019.09.18 |
|---|---|
| [4] MySQL의 CRUD - INSERT, SELECT, UPDATE, DELETE (0) | 2019.09.18 |
| [3] MySQL 테이블의 생성 (0) | 2019.09.18 |
| [2] MySQL의 구조 (0) | 2019.09.18 |
| [1] MySQL 설치 - Bitnami, codeanywhere (0) | 2019.09.17 |



